3D / Human-Centric Scene Understanding & Multimodal Understanding and Generation

Direction 1: 3D / Human-Centric Scene Understanding
Pose Estimation
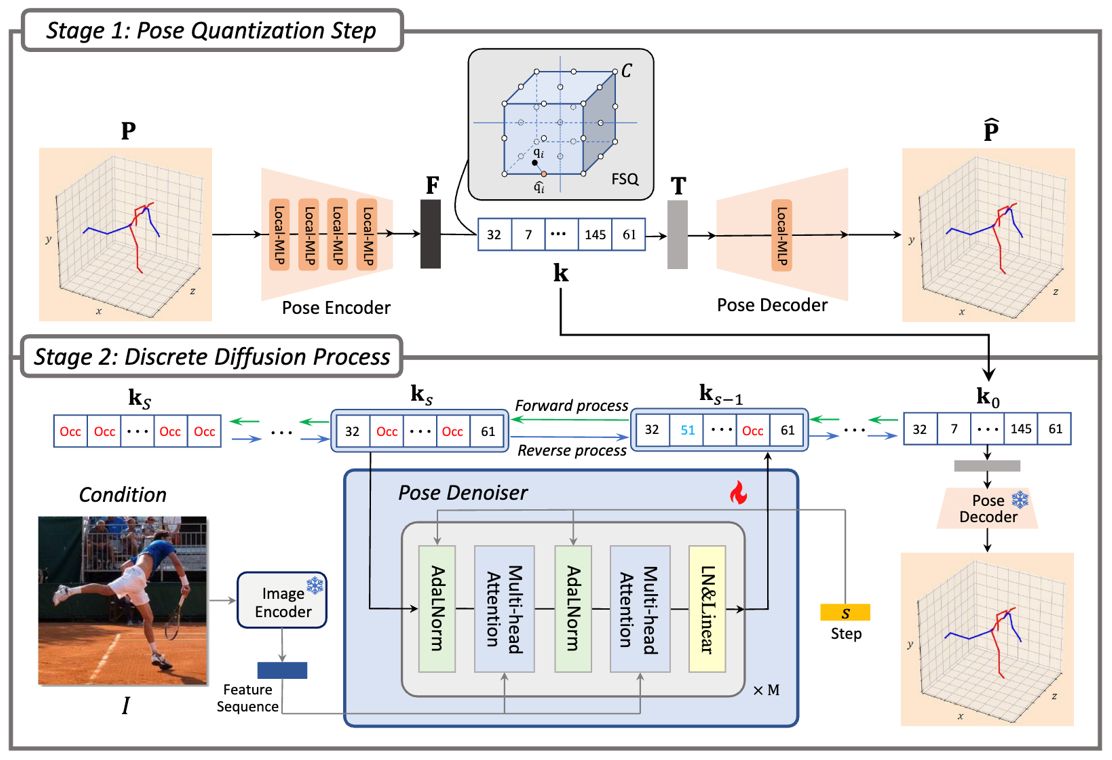
Di2Pose: Discrete Diffusion Model for Occluded 3D Human Pose Estimation (NeurIPS'24)

3D Modelling and Editing
View-Consistent 3D Editing with Gaussian Splatting (ECCV'24)

Scene Understanding
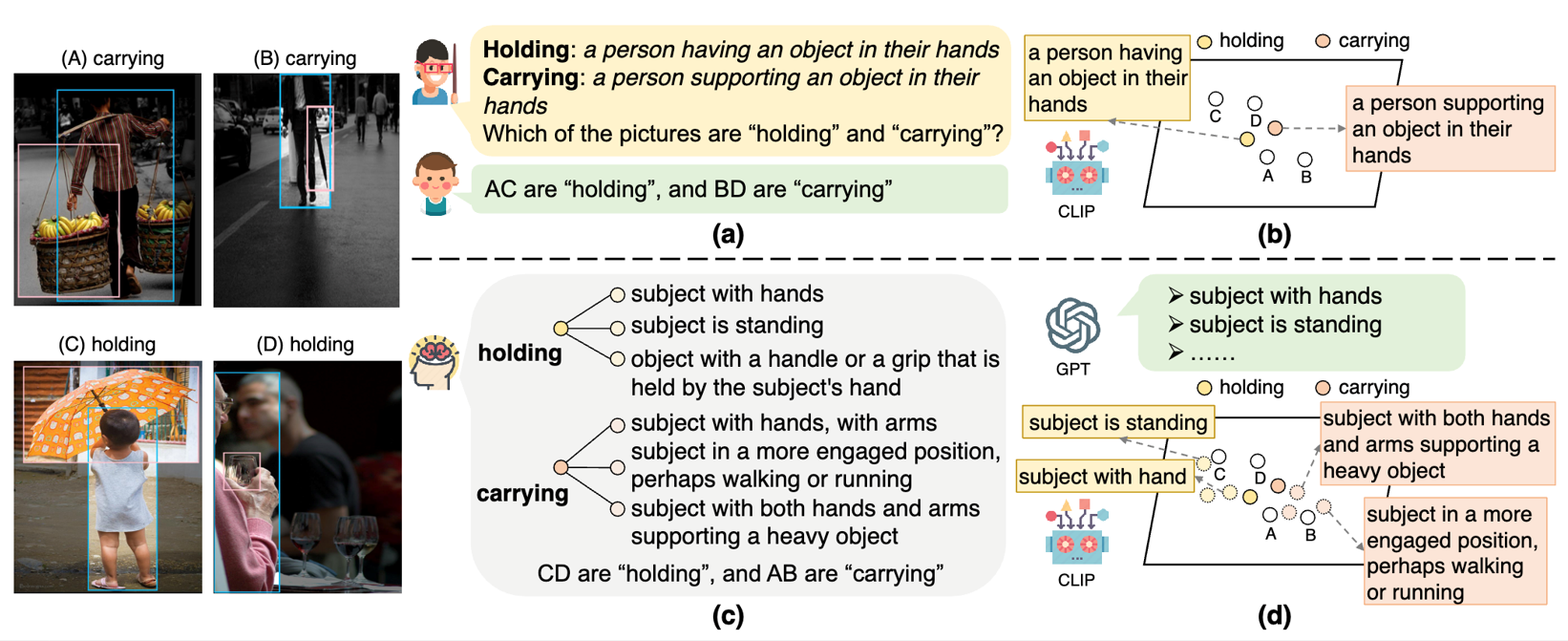
Zero-shot Visual Relation Detection via Composite Visual Cues from Large Language Models (NeurIPS'23)
Direction 2: Multimodal Understanding and Generation
Multimodal Understanding
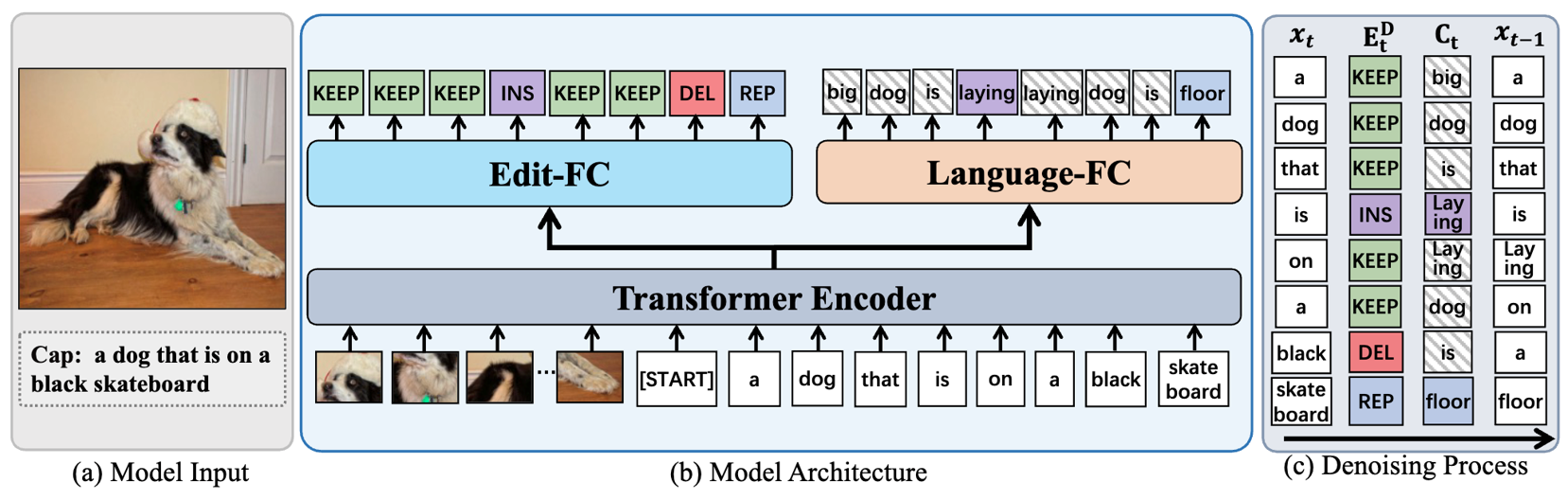
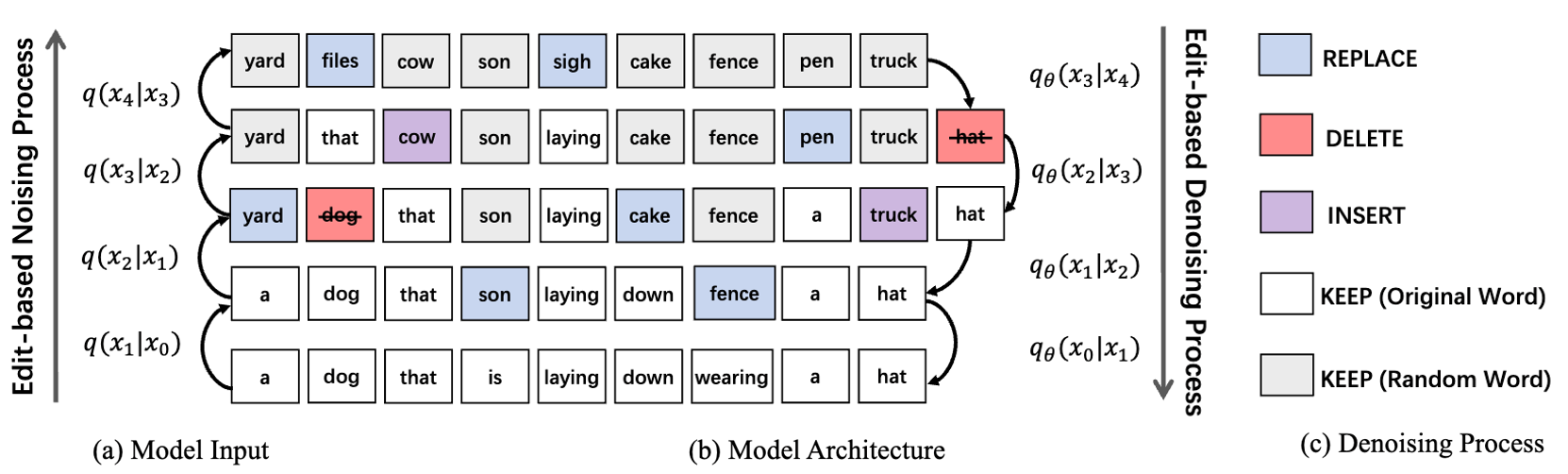
DECap: Towards Generalized Explicit Caption Editing via Diffusion Mechanism (ECCV'24)
Multimodal Generation
- IterIS: Iterative Inference-Solving Alignment for LoRA Merging (CVPR'25)
- DisPose: Disentangling Pose Guidance for Controllable Human Image Animation (ICLR'25)
Interleaved Understanding and Generation
CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation (CVPR'25)